SOA 北美精算师考试 PA 的学习大纲,备考必看。各module的总结。
PA是SOA准精阶段的第七门:Predictive Analysis(预测分析),再加上FAP就完成了准精。
以下会结合PA的module和考试内容一起总结:
- Module 1-2 对于R的基础介绍(下载、基础代码,比较基础就不在这过多介绍了)
- Module 3 ggplot
- Module 4 Describing variables/Missing data/Data design/Univariate data exploration/Bivariate data exploration
- Module 5 Data issue/resolutions
- Module 6 Genelarized linear model (GLM) /regularization
- Module 7 Decision tree/bagging/boosting
- Module 8 PCA/K-means clustering
- Module 9 Communication
Module 3 ggplot
主要是辅助report的撰写,visualization来使得文章更数据化和具有描述性。
Histogram/bar chart 柱状图
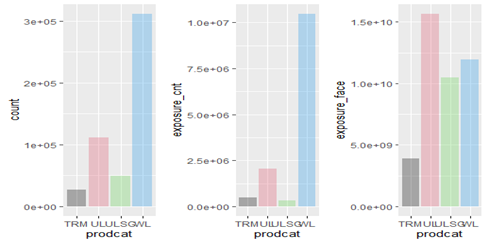
主要是density和count的函数,对于单一变量的作图。比如整个数据库中age在每个点的分布。以下图表为举例,Prodcat指产品类型。左图1为不同产品类型的数量累计图形,可用fill=#对柱状图进行染色,左图2、图3不同产品类型的索赔件数(count
amount)和索赔额(face
amount),可用weight=#来修改y轴的坐标属性,从单一变量的密度和分布函数变成了两个变量的相关分布图形。
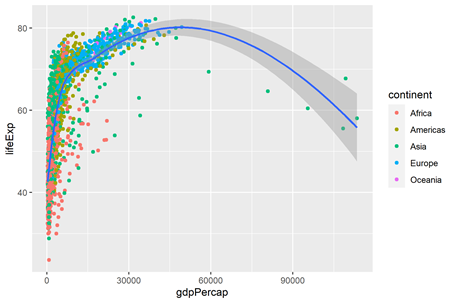
Line/point/smooth 散点图和趋势线
通常为两个变量的相关图形。smooth和line的区别为smooth可用把该趋势线的标准差在图形中变现出来。如下图的阴影部分就是该线条的标准差。LifeExp(生活成本)与gdpPercap(人均gdp)之间的关系,然后不同颜色的点代表不同的continent(洲),可以用color=#来上色。
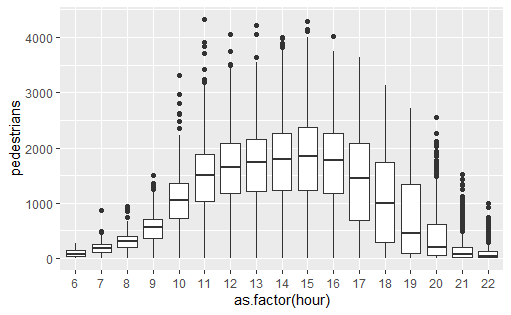
Boxplot 箱型图
主要是展示以某一变量为基准(y轴)在不同情形(x轴)的分布,分布主要显示first
quantile,中位数,third
quantile和偏差点。如以下事例,箱型的上下边分别表示first quantile和third
quantile,中位数为箱型图案中间的线,离箱型图案较远处的散点为偏差点。下图表示在不同时点,路上行人的数量差异。
Module 4 Describing variables/Missing data/Data design/Univariate data exploration/Bivariate data exploration
(对于数据格式的整体完善和处理,从而辅助于之后的visualization)
Type of data
对于将在模型里用到的数据主要分为factor和number(或integer)的形式,而在考试中通常会出现character格式的数据,需要转换成factor,如以下代码表示:
1
data$weather<-as.factor(data$weather)
Describing variables
主要分为target variables和predictor variables,如module 3里boxplot举的事例,target就是y轴的pedestrians,predictor则是x轴的hour。
Missing value的处理在考试中通常分为以下几种: - remove columns/ rows,直接移除行或列,移除列的主要原因通常会是该变量对于预测无实质性的影响(significant effect),移除行的原因则是,移除该数组对于整体sample无较大影响。 - replace with “unknown”,如果移除行数较多,对于数组的完整性造成影响,则会以unknown的变量表示。 - 还有mean,median,mode这三种方法来处理missing values。由于在现实生活中的缺乏操作性,所以通常很少用。
Data design
通常是对于数据进行相关处理,主要有Oversampling和Undersampling两种方法,考试偶尔也会考到某一个variable的granular(颗粒度),越详细的数据分类,颗粒度就会高,从国家到省到市到区到镇,就是颗粒度越来越高的一个过程。
Univariate data exploration
是指单变量的分布,通常是指数据的numeric statistics或者summaries,在ggplot中多以histogram和bar chart的形式体现。
Bivariate data exploration
主要分为三种 categorical versus numerical、categorical versus categorical和 numerical versus numerical,通常展示出来的图形都是条件分布的。下图所示就是在histogram和boxplot展示的bivariate exploration。两种exploration通常会在考试中的task1、2、3中要求对整个dataset的数据有所描述而用到。
Module 5 Data issue/resolutions
此部分主要描述了outliers的类型,分为errors(错误值,如age显示140)和natural(自然偏差height显示2.2m,实际存在,但与样本其他点偏离较大)。
bivariate data exploration的作图,numerical对应numerical多用scatterplot和point的方法,categorical对应categorical多用histogram和bar chart,numerical对于histogram则多用box plot。
考试时还会用到 library(dplyr)的package来处理数据,通常都会提供code,主要用到的是filter,mutate和summarise,偶尔会有select和arrange的用法。以filter举例,就是做条件筛选数据,以下这条code就是表示我们只需要数据里年龄大于或等于18的数据。
1 | data<-data %>% filter(data$age>18) |
Module 6 Genelarized linear model (GLM) /regularization
以下为四种常见的所有模型和default link function,用来应对于不同的实际情景,以poisson分布为例,主要应对于预测分析target variable大于零的情形,如街上的行人数量。
| Link (distribution) | link function (default) |
|---|---|
| Gaussian | identity |
| Poisson | log |
| Gamma | inverse |
| Binominal | logit |
既然有了模型,随之而来的就是model selection,用相关的方法来判断模型的好坏。主要方法会有AIC,BIC和Deviance。常见的情形是更小的系数代表更好的模型。在比较系数高低的同时,是用backward selection或者forward selection来进行模型变量的选择。顾名思义,backward selection是逆向选择,模型从完整的模型对变量一个一个消减来观察AIC等系数的变化;forward selection则是正向选择,模型从唯一的截距开始增加变量。
Regularization则是对于过于复杂的模型进行变量削弱和衰减(shrinkage),主要方法为ridge,lasso和elastic net(ridge和lasso的结合)。更多的情形下会用到lasso,因为lasso可用把变量的系数(coefficient)衰减到0,而ridge只能衰减到接近于0。也就是lasso相对于ridge,可用让我们在分析模型时,得到一个更简单的模型。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。




